The next global IT meltdown is already in the making, as evidenced by CrowdStrike's recent failure.
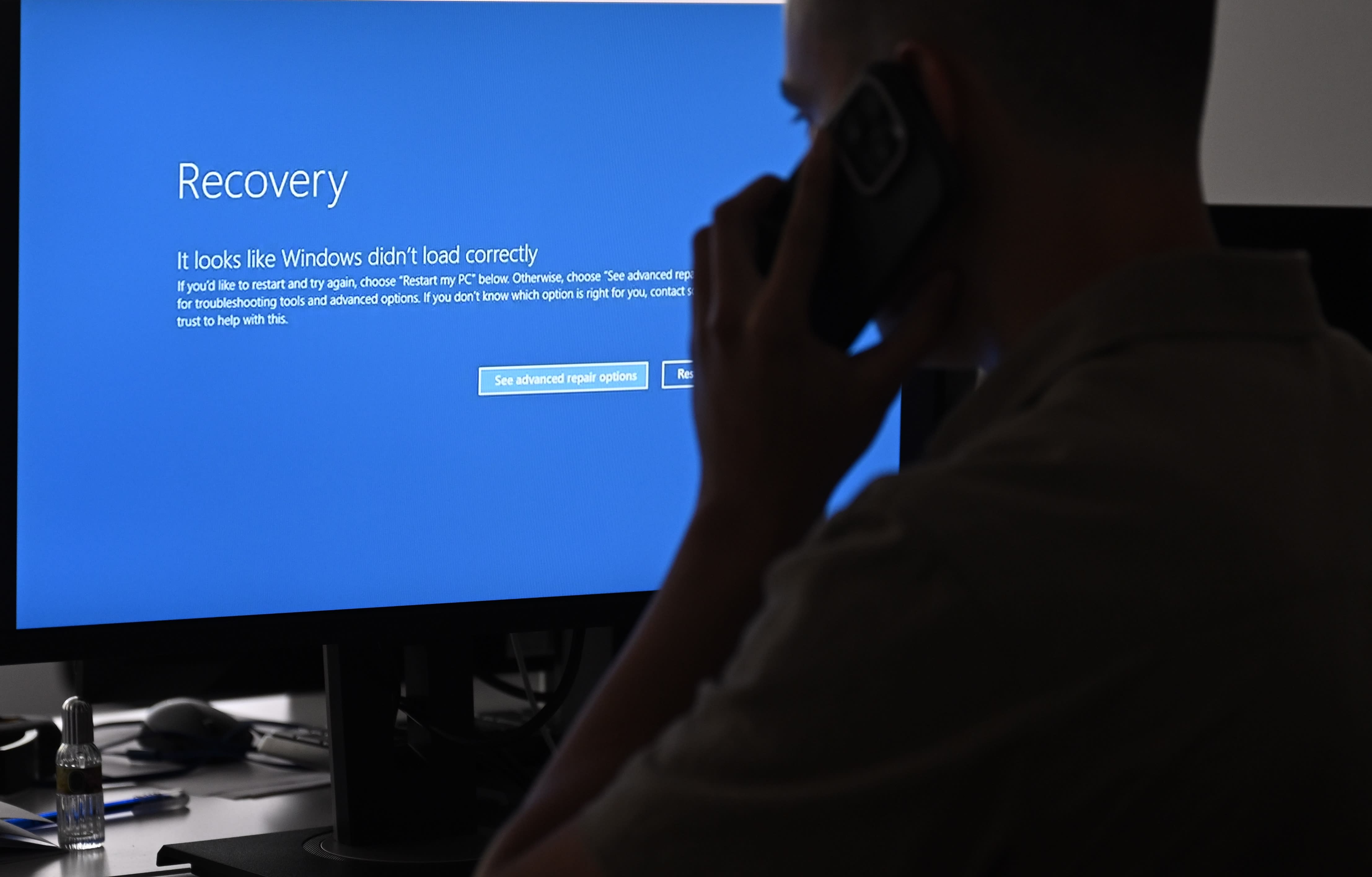
- The CrowdStrike software bug that caused a global IT outage has led IT experts to criticize the current system's centralized security approach.
- To safeguard a business from technical failure resulting in compromise, it is crucial to implement incremental software updates and incorporate redundancy into systems.

On Friday, the worldwide computer screens turned blue, causing flights to be grounded, hotel check-ins to be impossible, and freight deliveries to come to a halt. Due to the situation, businesses were forced to resort to using paper and pen. Initially, there were suspicions of a cyberterrorist attack, but the truth was much more straightforward: the issue was caused by a faulty software update from CrowdStrike.
Nick Hyatt, director of threat intelligence at security firm Blackpoint Cyber, stated that it was a content update in this scenario.
The update was felt globally because CrowdStrike has a vast customer base.
"A single error has resulted in devastating consequences. This demonstrates the significant impact of technology on our daily lives, as seen in various establishments such as coffee shops, hospitals, and airports," Hyatt stated.
Hyatt says that Falcon, the CrowdStrike monitoring software, has deep connections to monitor for malware and other malicious behavior on endpoints, including laptops, desktops, and servers. Falcon updates itself automatically to account for new threats.
CrowdStrike's auto-update feature rolled out buggy code, resulting in a catastrophic fallout, according to Hyatt.
Organizations with complex systems may struggle to reverse the global cascade of damage even if CrowdStrike quickly identifies the problem and restores systems within hours.
"Eric O'Neill, a former FBI counterterrorism and counterintelligence operative and cybersecurity expert, stated that organizations experience downtime of three to five days before things are resolved."
The outage occurred on a summer Friday when many offices were closed, and IT support was scarce to resolve the issue.
Software updates should be rolled out incrementally
CrowdStrike's update should have been rolled out incrementally, as one lesson learned from the global IT outage, according to O'Neill.
O'Neill advised against rolling out Crowdstrike updates to everyone at once. Instead, he suggested sending it to a group for testing and implementing levels of quality control.
According to Peter Avery, vice president of security and compliance at Visual Edge IT, the product should have been tested in various environments before its release.
He believes additional safeguards are necessary to prevent similar failures from occurring in the future.
Avery stated that companies require proper checks and balances to prevent a single person from making decisions that could harm the company. He also pointed out that mistakes can occur when someone selects the wrong file to execute.
A single error in a system can lead to a catastrophic domino effect across industries, functions, and interconnected communications networks, as the IT industry refers to this as a single-point failure.
Call to build redundancy into IT systems

Companies and individuals may increase their cyber readiness in anticipation of Friday's event.
Avery stated that the larger context is the vulnerability of the world, which is not limited to cyber or technical problems. Numerous factors can lead to disruptions, including solar flares that can disrupt communications and electronics.
Javed Abed, an assistant professor of information systems at Johns Hopkins Carey Business School, stated that Friday's meltdown was not a reflection of Crowdstrike or Microsoft's cybersecurity capabilities, but rather a reflection of how businesses view cybersecurity. Abed emphasized that businesses should stop viewing cybersecurity services as a cost and instead recognize them as an essential investment in their company's future.
Businesses should be doing this by building redundancy into their systems.
A single point of failure should not halt a business, and that is what occurred," Abed stated. "Relying solely on one cybersecurity tool is not sufficient, as cybersecurity 101 teaches us.
What happened on Friday was more expensive than adding redundancy to enterprise systems.
Abed expressed the hope that the wake-up call would prompt business owners and organizations to revise their cybersecurity strategies.
What to do about 'kernel-level' code
The lack of cybersecurity leadership and the view of cybersecurity, data security, and the tech supply chain as "nice-to-have things" within enterprise IT is a significant issue, according to Nicholas Reese, a former Department of Homeland Security official and instructor at New York University's SPS Center for Global Affairs.
Reese stated that the kernel-level code responsible for the disruption should receive the highest level of scrutiny, with separate processes required for approval and implementation, and accountability necessary.
The ecosystem is facing a persistent issue with third-party vendor products, all of which have vulnerabilities.
Reese stated that it is challenging to predict the next vulnerability in the ecosystem of third-party vendors. However, it is crucial to try, even though it is almost impossible. He emphasized that businesses must focus on backup and redundancy and invest in it, but they often cannot afford to pay for things that might never happen. Reese acknowledged that it is a difficult case to make.
Technology




















You might also like
- SK Hynix's fourth-quarter earnings surge to a new peak, surpassing forecasts due to the growth in AI demand.
- Microsoft's business development chief, Chris Young, has resigned.
- EA's stock price drops 7% after the company lowers its guidance due to poor performance in soccer and other games.
- Jim Breyer, an early Facebook investor, states that Mark Zuckerberg has been rejuvenated by Meta's focus on artificial intelligence.
- Many companies' AI implementation projects lack intelligence.